プログラミング:藤野 和志
概要
最近の人工知能研究のブームをけん引しているのはニューラルネットワークです.特に識別に関する性能が成熟化しました.ただ,ニューラルネットワークには,膨大な計算が必要なネットワーク最適化を要したり,膨大な入力データを要する点が脳と乖離するという指摘があります.我々には,次世代の技術基盤を作りたいという思いがあります.人間の脳の高度な機能は,大脳新皮質にあるといわれており,その本質は予測にあると考えられます.我々は予測知能の実現に向けた研究をしています.
大脳新皮質学習
脳機能をモデル化して利用する研究は多種多様で,簡素なモデルを利用するものから,精緻なモデルを利用するものまであります.その中で,我々はJ. Hawkinsらによって提唱された階層時間記憶(Hierarchical temporal memory, HTM)の概念に注目し,それを具現化したアルゴリズムのひとつである大脳新皮質学習アルゴリズム(Cortical Learning Algorithm, CLA)の研究をしています.
CLAは,人間の大脳新皮質の仕組みを模倣した時系列予測法であり,異常検知に利用されることもあります.入力データを離散表現にして取り扱うこと,シナプスを簡素なアルゴリズムで構築するところに特徴があります.以下,簡単にCLAについて紹介します.
構成
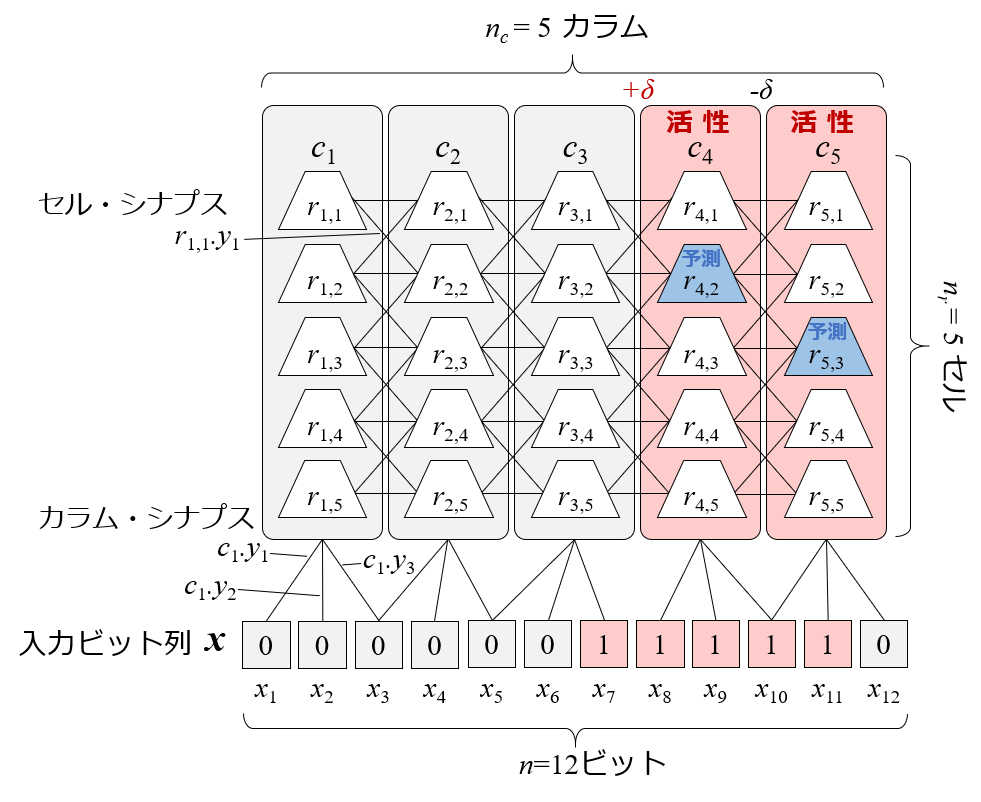
CLAの学習器の構成を以下に示します.CLA の学習器全体をリージョンと呼びます.リージョン内には,複数のカラムを用意します.それぞれのカラム内には,複数のセルを用意します.入力データはバイナリビット列で表現し,各ビットとカラムの間にシナプスを配置します.また,セルとセルの間にもシナプスを配置します.
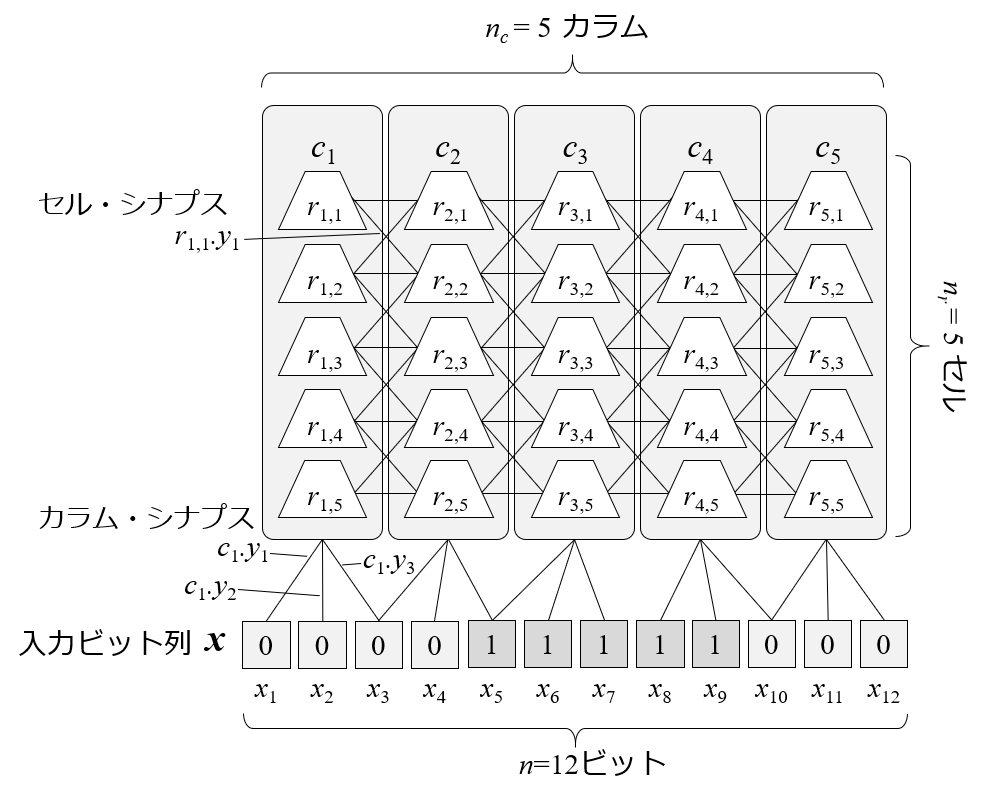
カラムは,入力データを学習器内の内部表現にするために使われます.
セルは,入力データの時系列を内部表現するために使われます.
空間プーリング
データビット1とシナプス接続のあるカラムを活性させ,入力データをカラムの活性パターンで内部表現にします.活性に貢献したシナプスは強度を高めます.この処理を空間プーリングといいます.
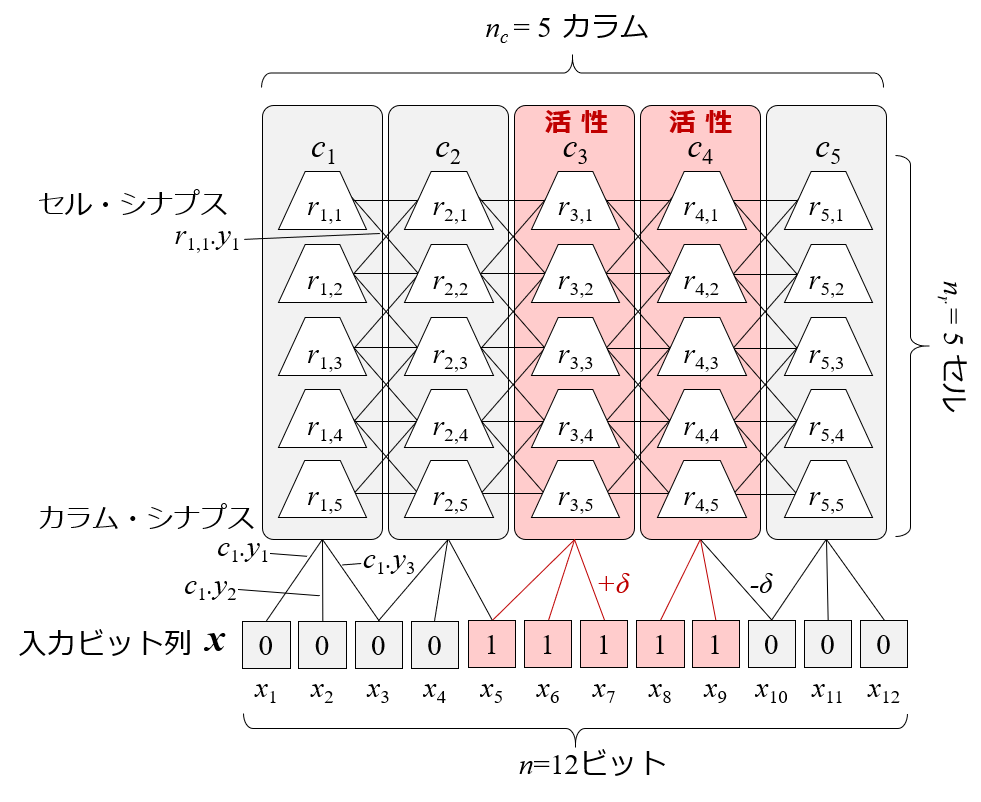
時間プーリング
空間プーリングにおいて,同じデータが入力されれば同じカラムが活性するのですが,
出現する文脈の違いを表現するために,そのカラム内セルをひとつずつ活性させて,文脈を表現します.
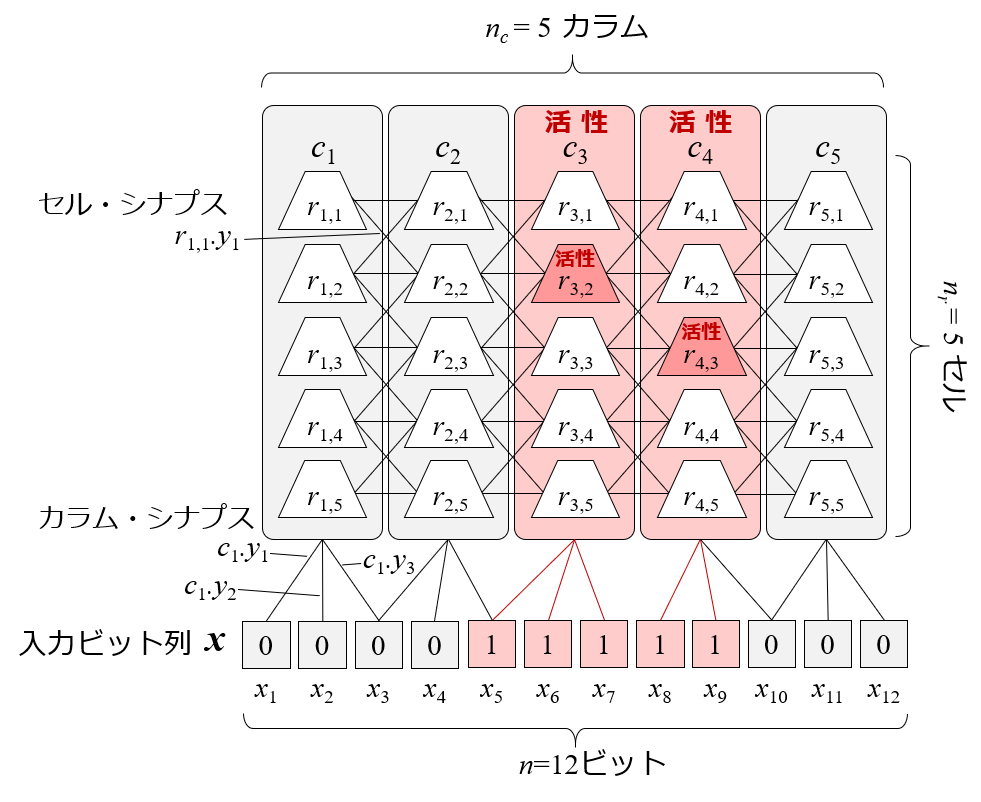
また,予測もセルによって行います.
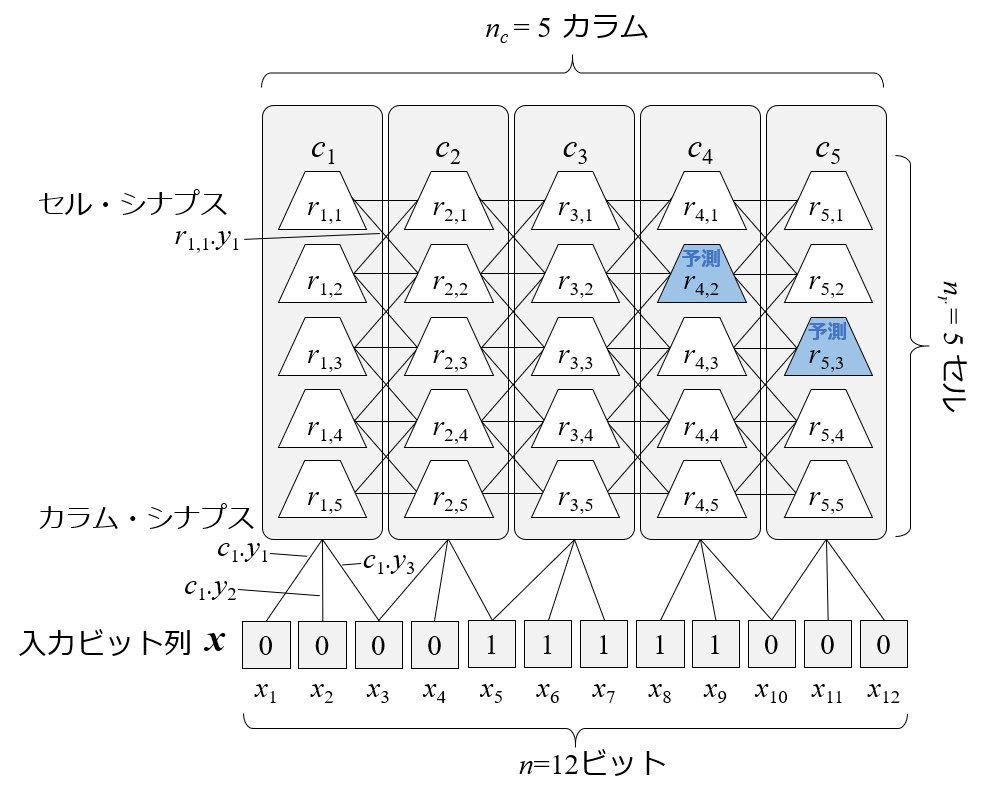
この場合,次状態でこれらのカラムが活性すると予測成功ということになります.
実験結果
実験結果を紹介します.カラム数は,2048に設定しました.1つのカラムおけるセル数は,32に設定しました.421ビットの入力データビットにしました.
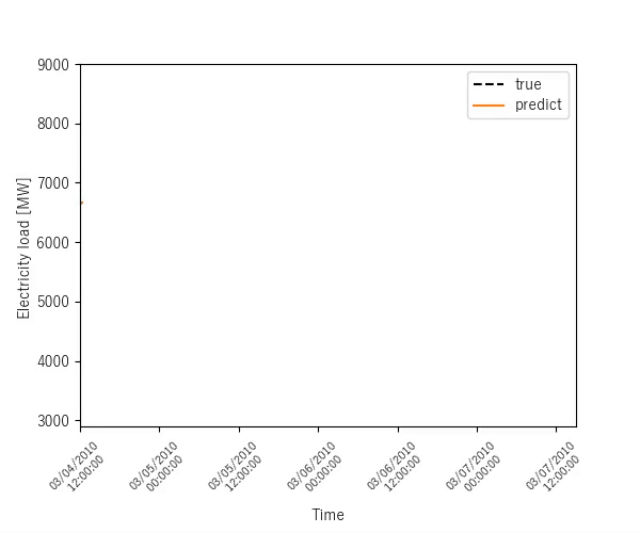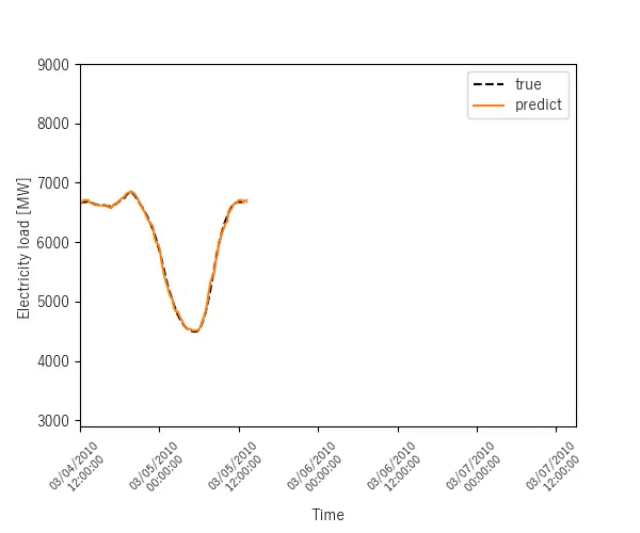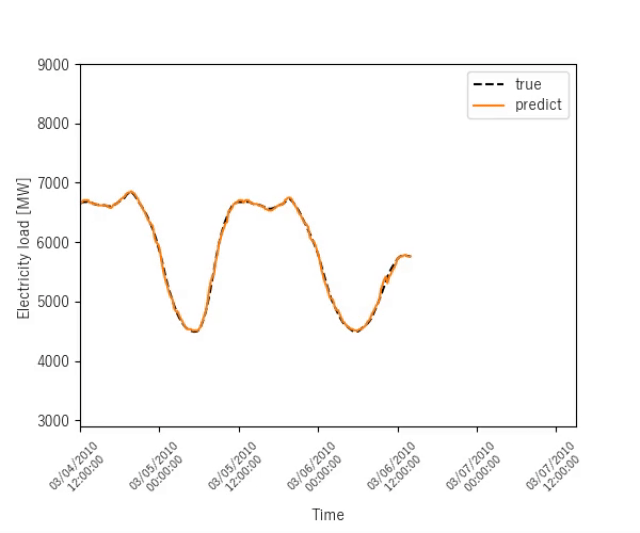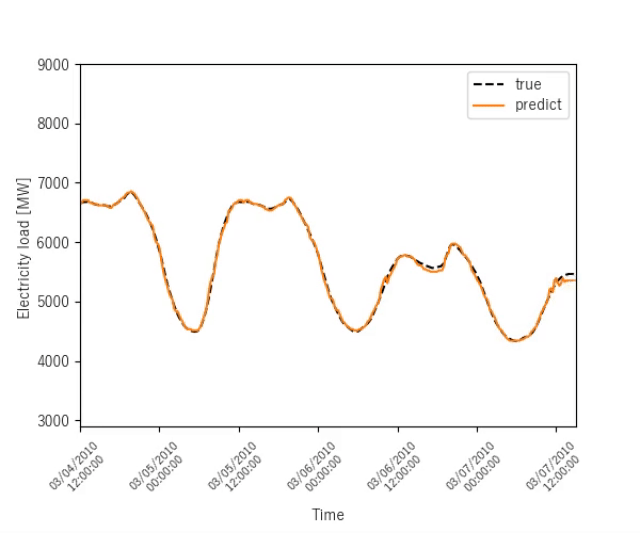
ニューヨークの電力消費量予測
ニューヨークの電力消費量を予測する結果を示します.
序盤
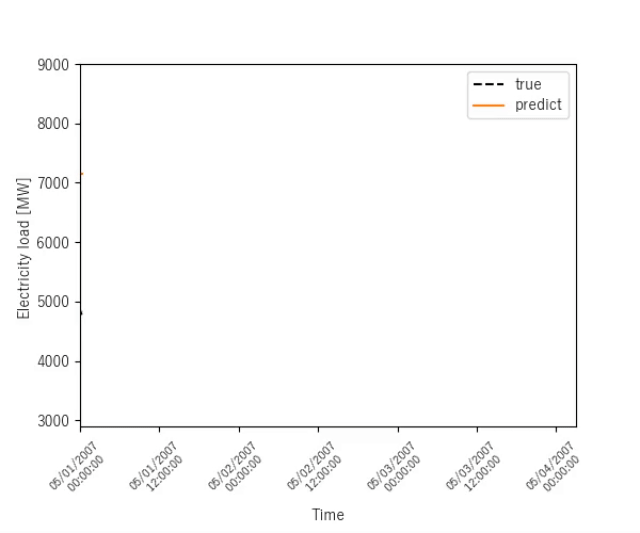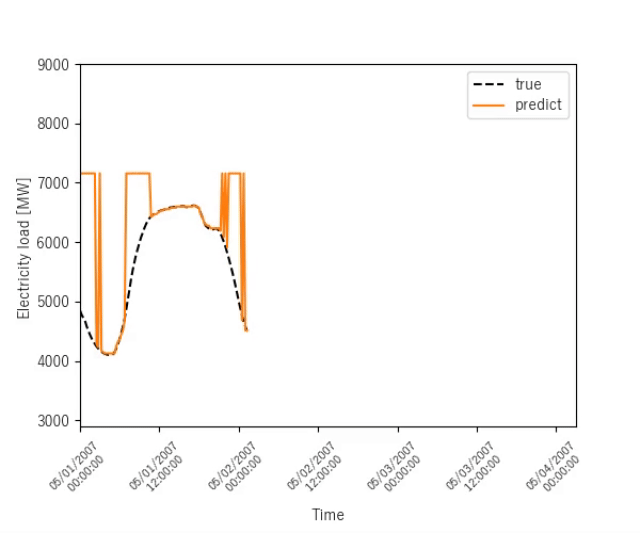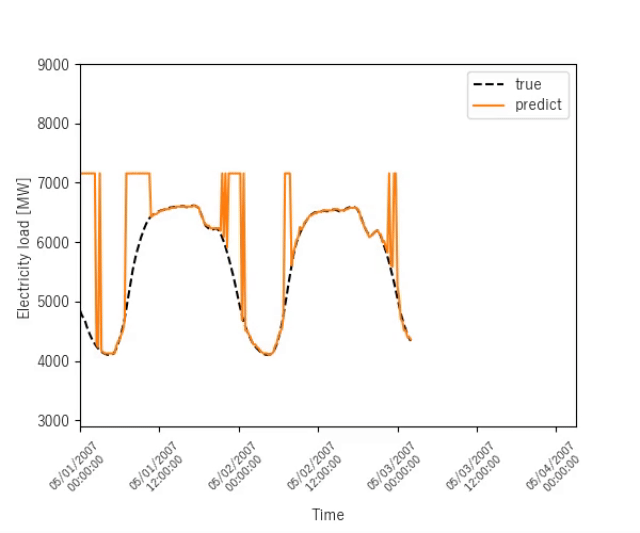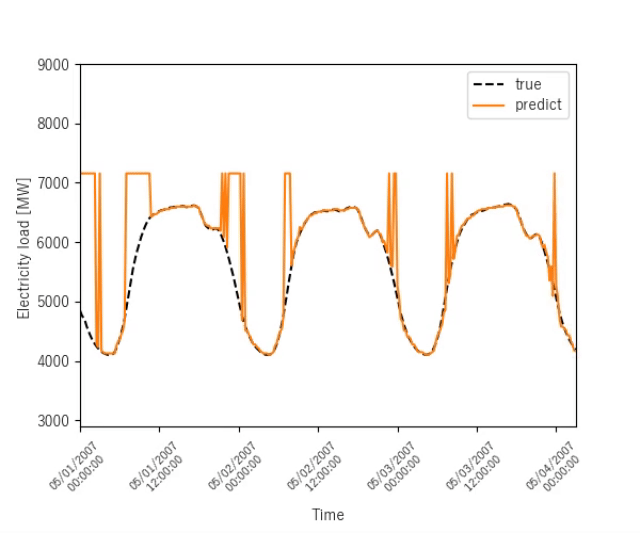
終盤
ニューヨークのタクシー需要予測
ニューヨークの電力消費量を予測する結果を示します.
序盤
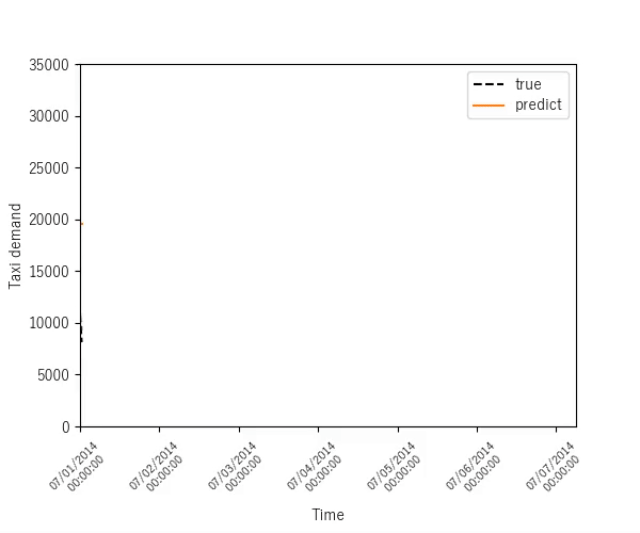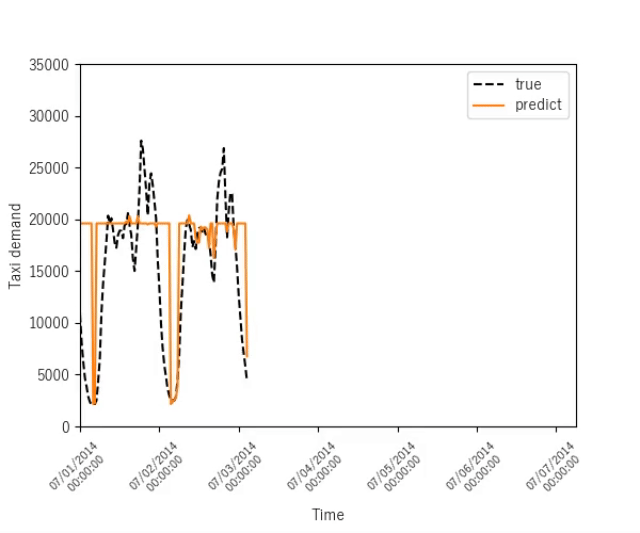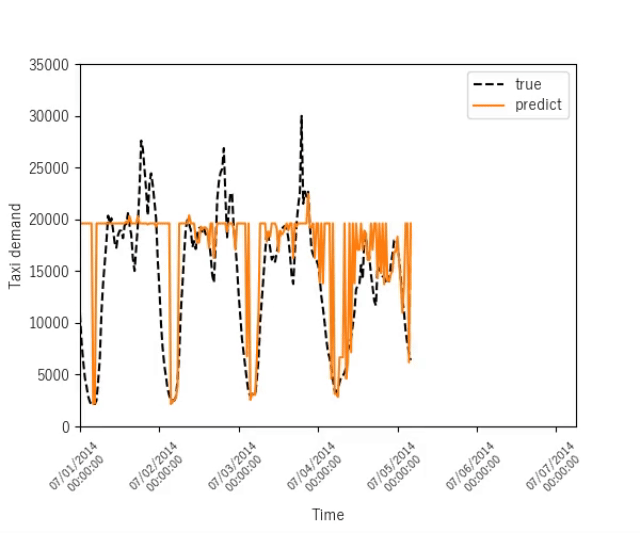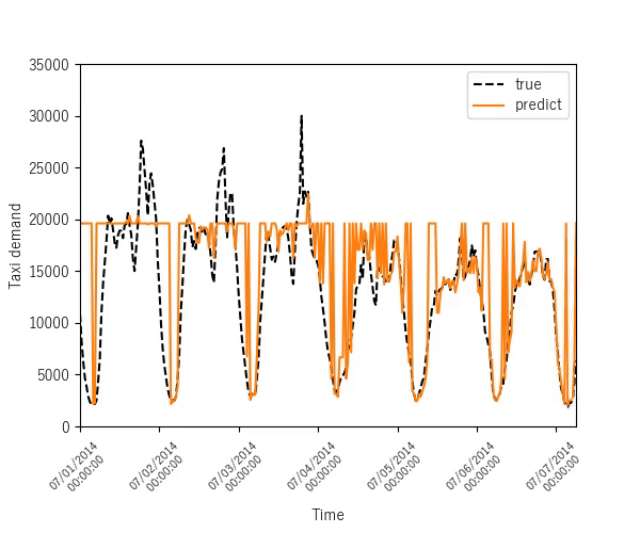
終盤
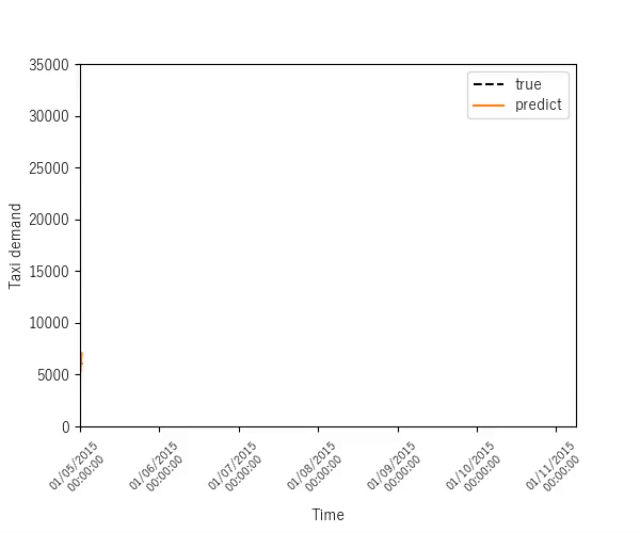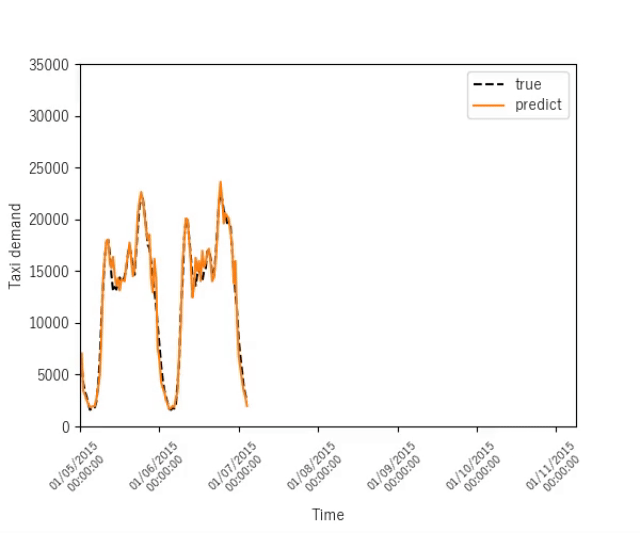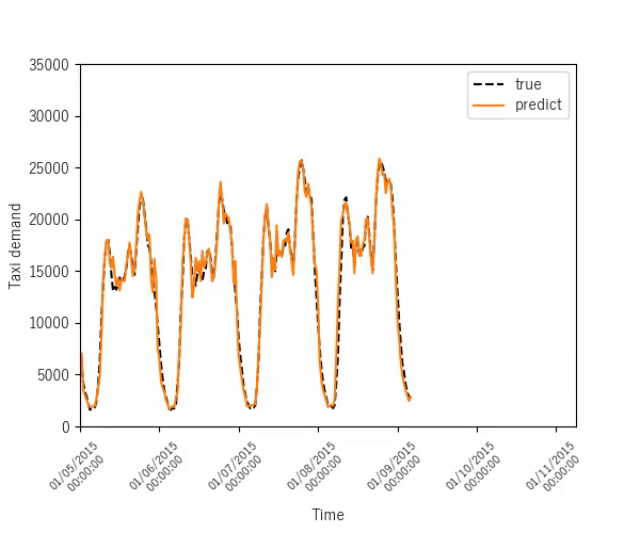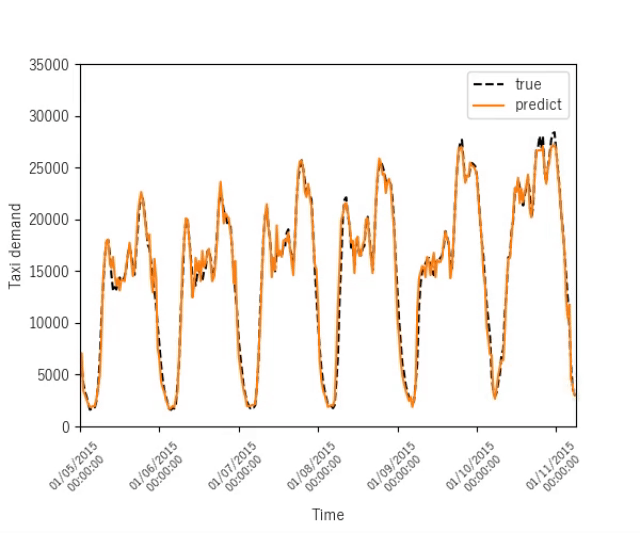
まとめ
我々が取り組んでいる階層時間記憶と大脳新皮質学習について紹介しました.詳細は,下記文献を参照されるのが良いと思います.今回紹介したのは基礎であり,特に我々はアルゴリズムの改良と,予測の適用可能範囲の拡大のための研究をしています.
- J. Hawkins, S. Blakeslee: On Intelligence: How a New Understanding of the Brain Will Lead to the Creation of Truly Intelligent Machines, Times Books, 2005.
- Hierarchical Temporal Memory (HTM) Whitepaper, https://numenta.com/neuroscience-research/research-publications/papers/hierarchical-temporal-memory-white-paper/